The New York Times: One Topic for All Content Since 1850
The New York Times uses Kafka end-to-end to publish its content. Without any extra database in the system, all articles going back to the 1850s are stored chronologically in a single topic.
Materialized views and KTables are exposed using Kafka Streams. Because there are different schemas, different teams, and different data formats, they didn't build any separate API or microservice layer just for publishing. All services consume their data and assets directly from Kafka; what they do with that data afterwards and where they store it is up to them.
When a new article or piece of content is published, it's pushed to that same topic in Kafka and becomes accessible to every service at the same time.
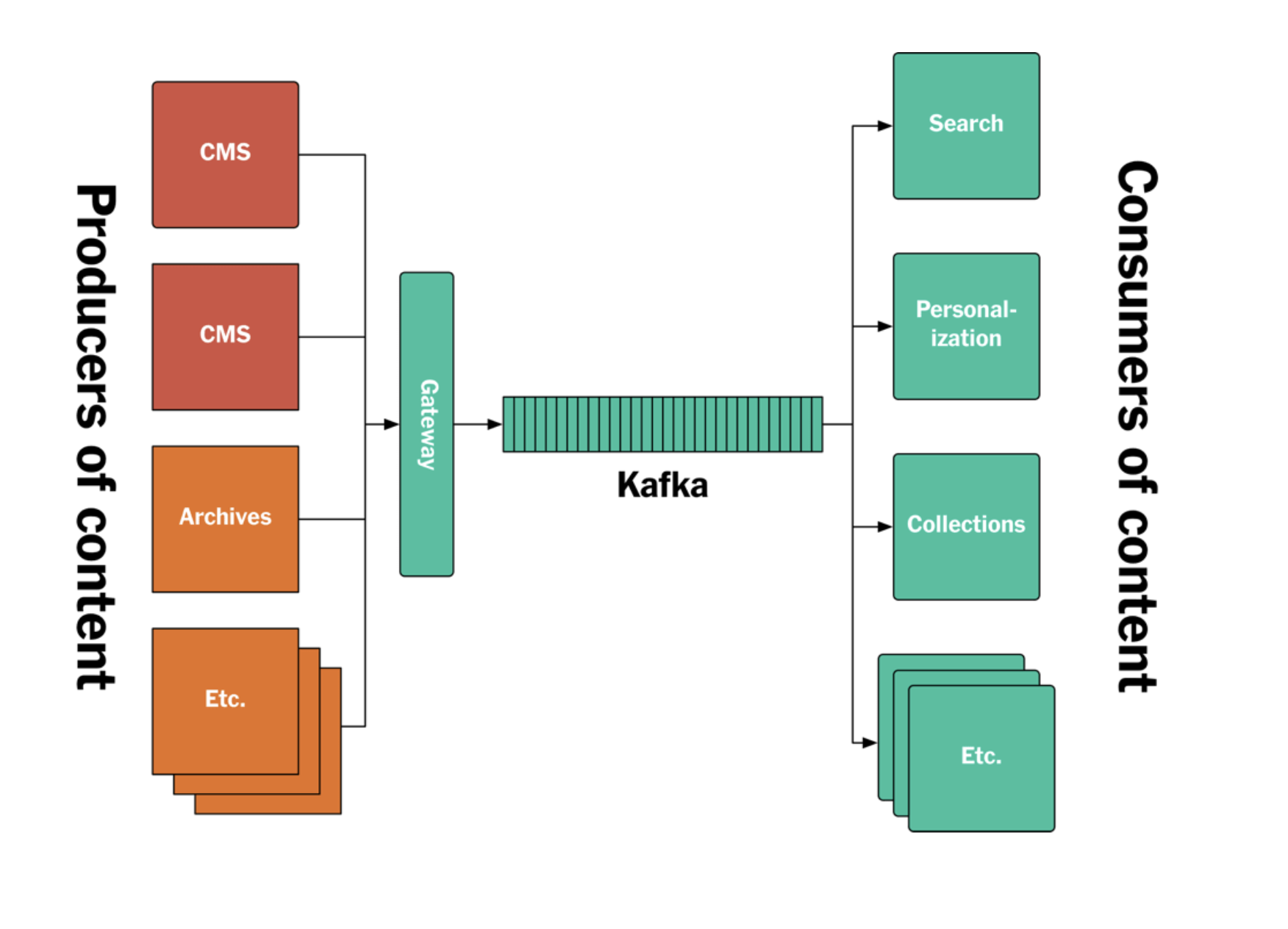
Figure 1: The new New York Times log/Kafka-based publishing architecture.

