The New York Times: One Topic for All Content Since 1850
The New York Times uses Kafka end-to-end to publish its content. Without any extra database in the system, all articles going back to the 1850s are stored chronologically in a single topic.
Materialized views and KTables are exposed using Kafka Streams. Because there are different schemas, different teams, and different data formats, they didn't build any separate API or microservice layer just for publishing. All services consume their data and assets directly from Kafka; what they do with that data afterwards and where they store it is up to them.
When a new article or piece of content is published, it's pushed to that same topic in Kafka and becomes accessible to every service at the same time.
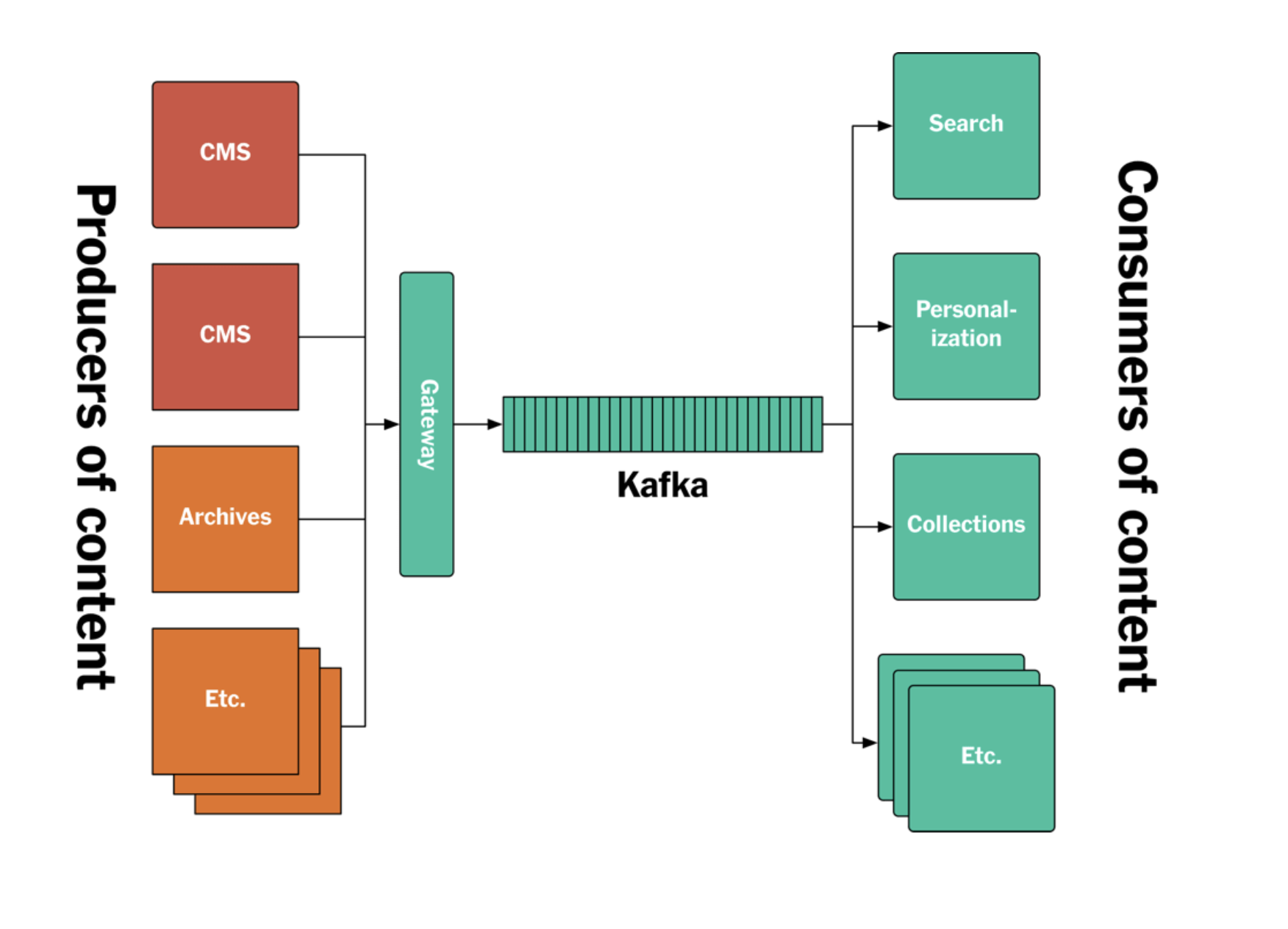
Figure 1: The new New York Times log/Kafka-based publishing architecture.
Pinterest: 50+ Clusters and 40M Messages per Second
Pinterest runs more than 50 Kafka clusters internally. They store user actions as files, send these files into Kafka, and the user action logs in Kafka are consumed by both batch and real-time applications. Spam detection, analytics, and recommendation systems all run on top of this pipeline. Internally, they handle around 40 million inbound messages per second.
Storage Choices and I/O Bottlenecks
They've also had issues with magnetic disks. When a broker fails and the system restarts, it has to replay from the write-ahead logs (WAL), which easily leads to high I/O wait times and therefore long recovery times. On top of that, because the CPU spends so much time waiting for synchronous disk operations to finish, it can't context switch efficiently and CPU I/O becomes a bottleneck.
In general, using anything that slows down I/O-like NAS or magnetic disks is not recommended in any distributed file-processing system, whether it's HDFS, a database, or an MQ.
Cost Optimization: Compression and Replication Factor
Their brokers run on EC2, and messages between brokers are sent in compressed form to reduce data transfer costs. By lowering the default replication factor of their dev and test clusters from 3 to 2, they achieved about 33% EC2 cost savings and 50% savings on data transfer.
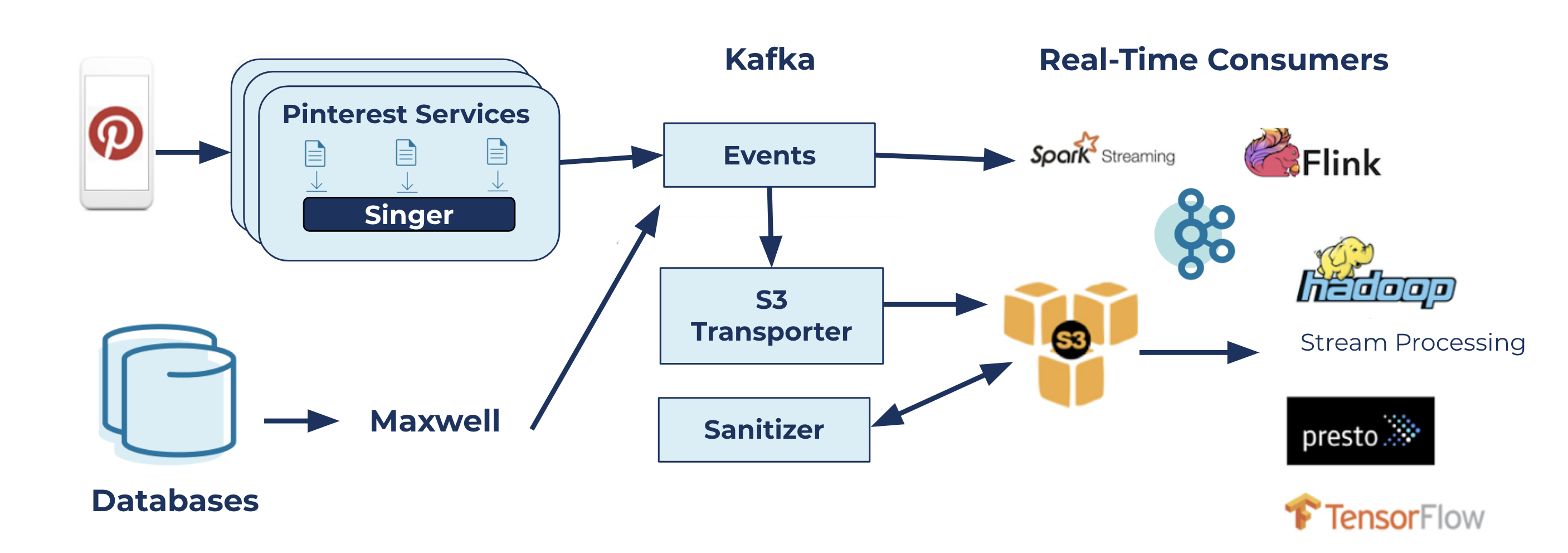
Figure 2: Pinterest's data transportation topology
A Large Enterprise: 40+ Clusters, 50 Engineers, No Shared Strategy
One anonymous enterprise customer has more than 40 Kafka clusters. They run every flavor: open-source Kafka, fully managed clusters, and semi-managed ones.
Across these clusters they had about 50 full-time people in 15 completely isolated teams doing Kafka DevOps work, with no shared data streaming strategy, tooling, or processes between teams. Most outages and incidents were caused by monitoring gaps, break-fix work, disk and network issues, missing upgrades, and misconfigurations. When one team fixed a problem, another team would eventually hit the exact same issue somewhere else.
Centralizing Kafka as a Service
In the end, they adopted Kafka-as-a-service from Confluent. The number of people working on Kafka dropped from 50 to 15, and instead of spending their time on bugs, upgrades, and similar chores, they were able to focus much more on their actual products (about 70% savings in engineering cost).
The main point here is that instead of running lots of tiny Kafka clusters, it's usually better to run a single large one, because it's easier to scale and tends to perform better. The more centralized the setup, the more standardization you get and the less maintenance effort you need.
The Trade-Offs of a Big Central Cluster
Of course, there are some technical and business trade-offs: upgrading a big cluster takes longer, and you have to plan for updating dependencies and clients as well, which is extra maintenance. And because the cluster is so large, moving data around or migrating it elsewhere can become significantly more expensive.